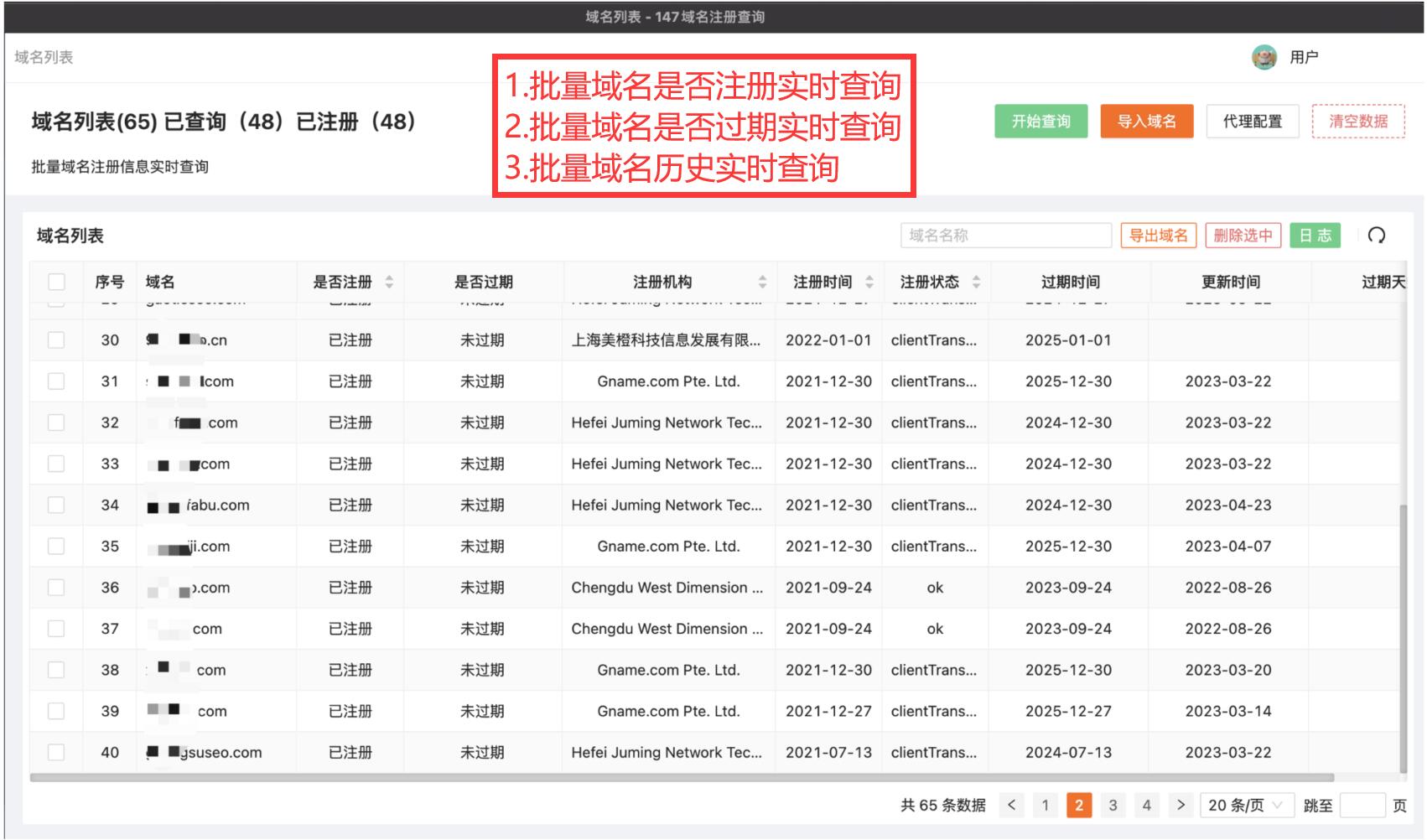
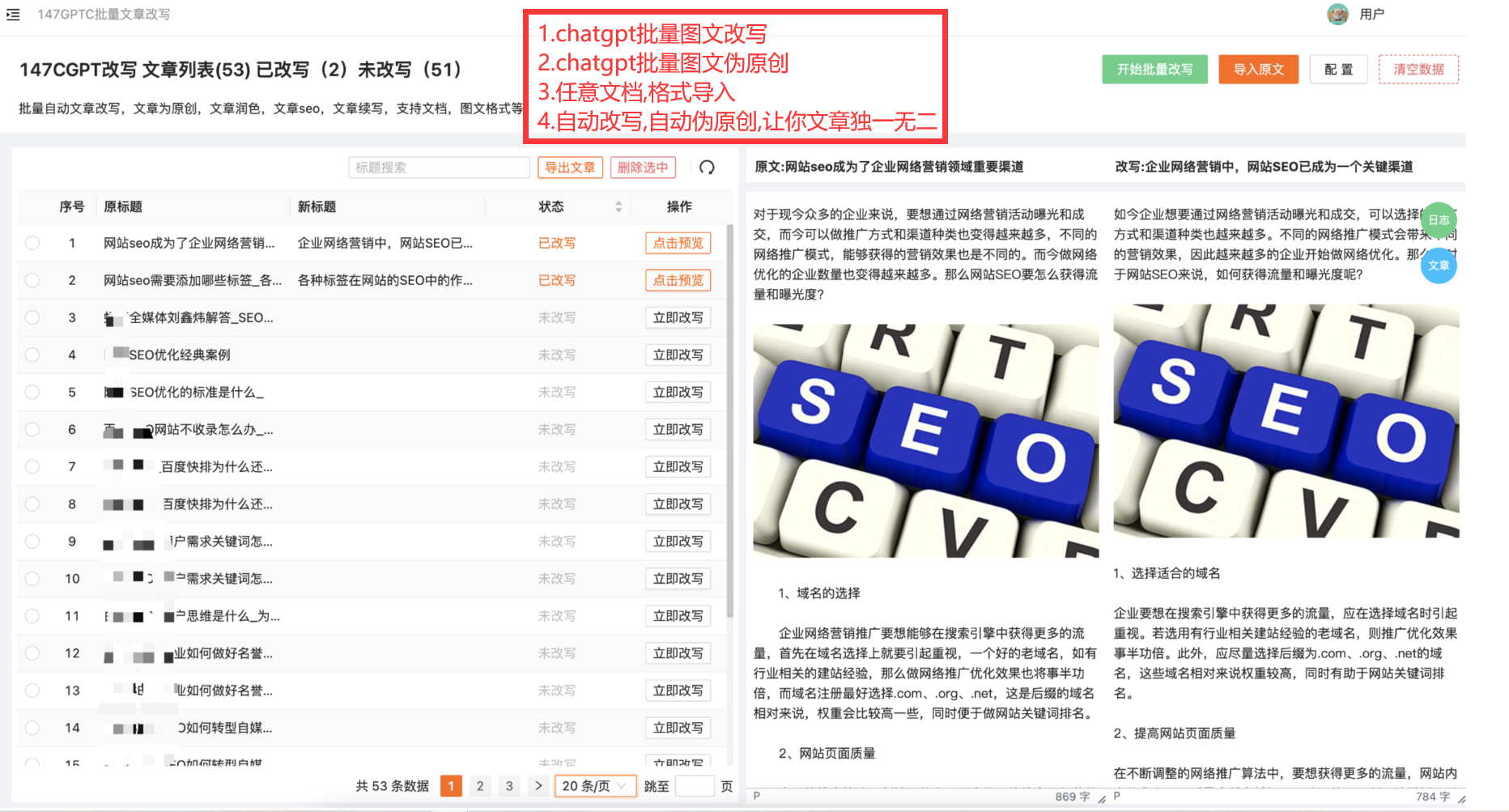
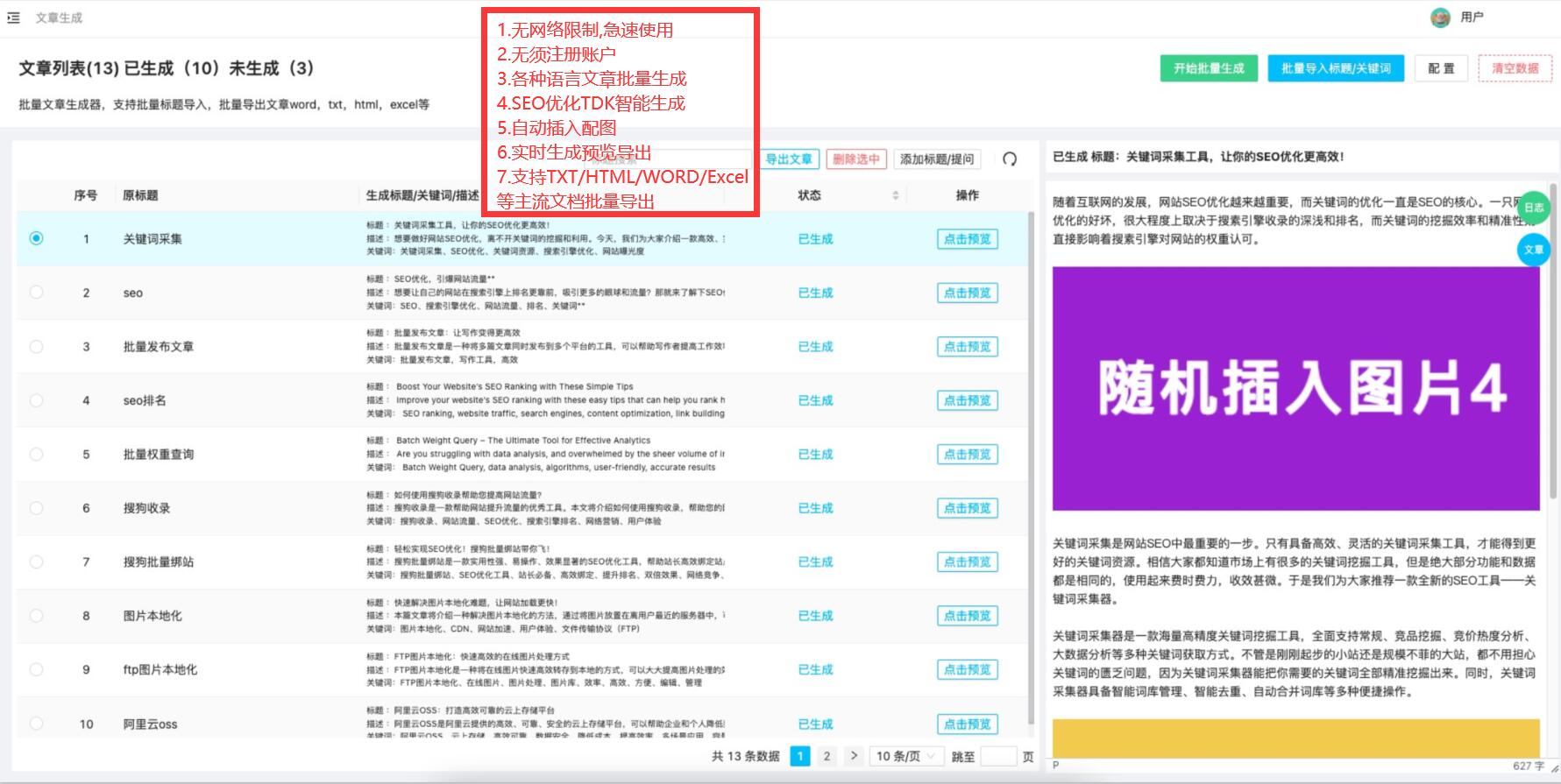
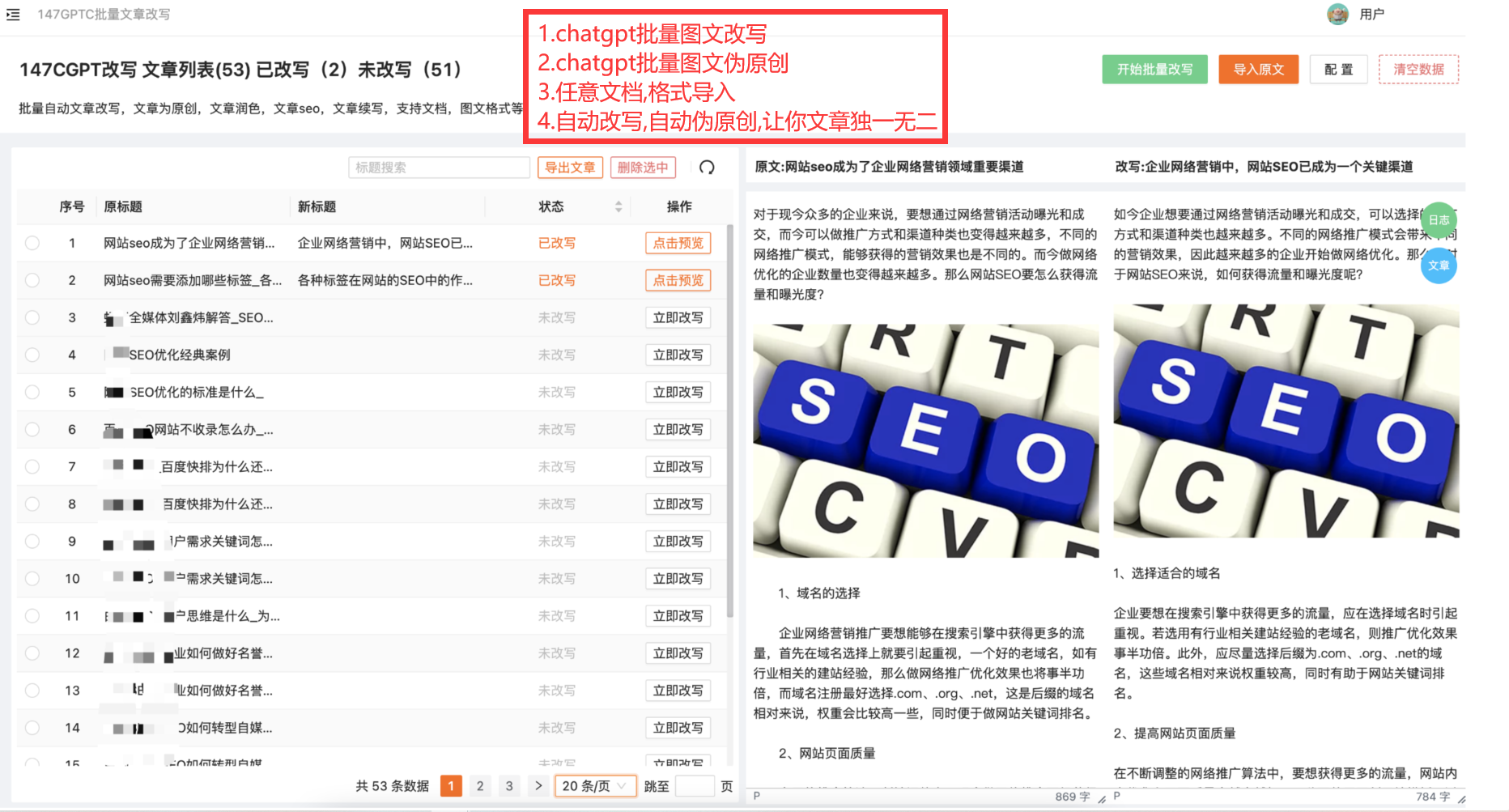
chatgpt批量伪原创的优势
ChatGPT是一个由OpenAI开发的强大的自然语言处理模型,它具有批量伪原创的优势,以下是这些优势:
模型能够处理大量的数据:ChatGPT通过训练大规模的语言模型来生成伪原创文本。这个模型拥有一个庞大的语料库,可以从中学习到所有可能的语言特征、约定和规则,进而创造出高质量的伪原创文本。
自然流畅的语言生成:由于ChatGPT是一个基于神经网络的模型,它的语言生成是自然流畅的,它可以生成与原始文本相似的语言风格,无论是在语法、句子结构还是用词方面,都能够准确地捕捉到原始文本的特点,使其生成的伪原创文本更具有可读性和自然度。
可定制化的生成:ChatGPT可以通过调整不同的参数和模型配置来生成不同风格的伪原创文本。因此,模型可以根据不同的需求对生成的文本进行调整和修改。
高效的批量生成:ChatGPT的架构允许它快速处理大量的文本数据,一次可以生成大量的伪原创文本。这使得ChatGPT成为处理大规模文本数据的首选模型,例如用于批量生成博客文章、商品描述等。
可持续的更新和优化:ChatGPT是一种强大的自我学习模型,因为它可以在大量数据上进行训练,通过自我学习和优化不断提高模型的性能,从而生成更准确、自然、流畅的伪原创文本。
综上所述,ChatGPT具有处理大量的数据、自然流畅的语言生成、可定制化的生成、高效的批量生成、可持续更新和优化等众多优势,使其成为处理伪原创文本的首选模型之一。目前市面上也有很多工具对接了chatgpt【详细如下图】导入标题即可批量伪原创!

如何使用Python连接ChatGPT来实现文本自动伪原创?
下面是一个简单的教程:
创建ChatGPT API密钥:首先需要在OpenAI网站上注册并创建ChatGPT API密钥,以便我们可以使用API与ChatGPT通信。
安装必要的Python库:使用pip安装必要的Python库,比如openai,requests等库。
使用Python连接API:导入openai等库,并使用您的API密钥连接到ChatGPT。下面是样例代码:
在这个样例代码中,我们使用了requests库执行请求,连接ChatGPT并生成文本。我们使用了DAVINCI CODEX模型,您也可以尝试使用其他可用模型,但需要注意不同模型的API链接和配置,详情请参阅OpenAI官方文档。

使用Python编写伪原创代码:根据您的具体需求编写伪原创代码,并将其输入到模型中以生成新的伪原创文本。下面是一个简单的伪原创代码示例:
在这个代码示例中,我们输入了一个中文文本,并使用gpt_response()函数让ChatGPT生成新的文章,最后将结果输出。可以使用循环等技术批量处理文章,根据您的具体情况进行调整。
检查并迭代:由于自然语言处理技术的局限性,生成的伪原创文本可能存在一些语法、逻辑或者语义问题。为了确保输出结果满足您的要求,您需要检查结果,并进行迭代测试,不断地调整代码和参数以达到您的最终目标。

总之,使用Python连接ChatGPT生成伪原创文本是一个有趣但也有挑战的过程,需要耐心和技术储备。但当您掌握了这个技术,将能够极大地提高您的工作效率和创作质量。