利用Python爬虫提取网页内容是一种高效、快捷的方式,可以帮助我们从互联网中获取所需的信息。本篇文章将介绍如何使用Python编写爬虫脚本,并简要说明其中的关键步骤和技术。

首先,我们需要安装Python和相关的第三方库。Python是一种简单易学的编程语言,拥有丰富的生态系统和活跃的开发者社区。通过使用第三方库,我们可以更高效地编写爬虫脚本。其中,常用的爬虫库包括BeautifulSoup、Requests和Scrapy等。
接下来,我们可以开始编写爬虫脚本了。首先,我们需要选择一个目标网页,并通过HTTP请求获取其HTML内容。可以使用Requests库发送HTTP请求,并获取服务器响应的HTML文档。之后,可以使用BeautifulSoup库解析HTML文档,提取我们感兴趣的内容。
在编写爬虫脚本时,需要注意合法和慎重的网络爬取行为。确保遵守网站的相关规定,合法地访问和提取内容。可以通过设置请求头、限制请求频率等方式来避免对目标网站造成不良影响。

在提取网页内容时,可以使用BeautifulSoup库提供的强大功能。它支持CSS选择器和XPath表达式,可以帮助我们快速、准确地定位需要提取的内容。通过对HTML结构的分析和解析,我们可以提取网页中的文本、图片、链接等信息。
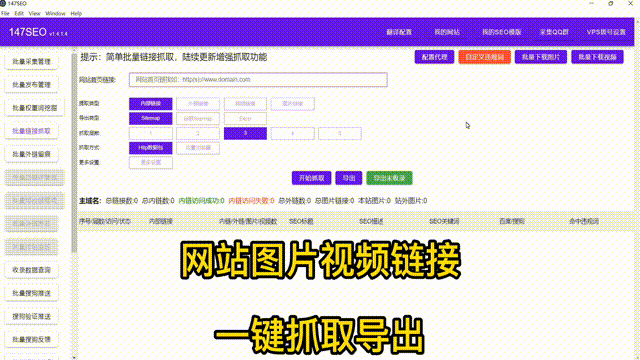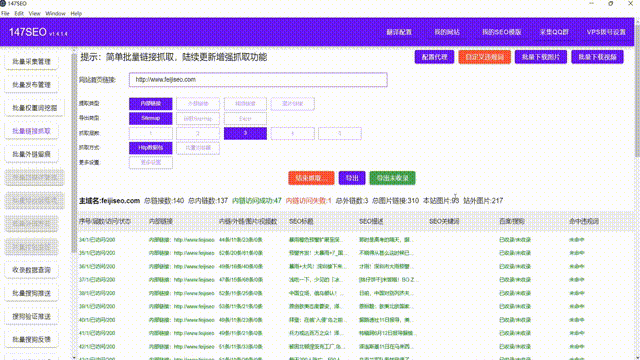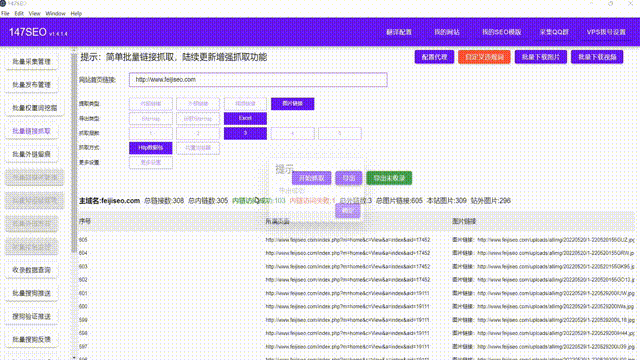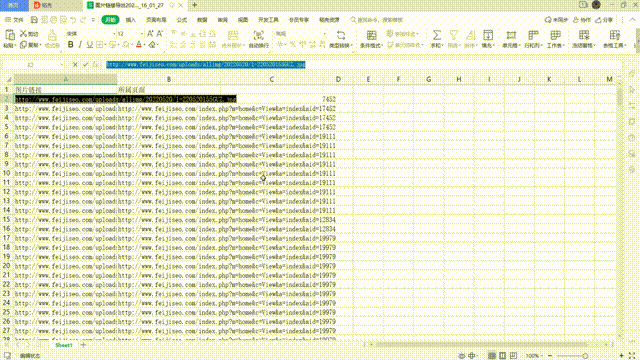
值得注意的是,爬取的网页内容可能存在规模较大的数据。因此,在处理和存储数据时,需要注意内存管理、数据格式转换等问题。可以使用JSON等格式保存提取的数据,方便后续的处理和分析。
除了基础数据提取,爬虫还可以进行其他高级功能的开发。例如,使用正则表达式进行数据匹配和提取,使用Selenium库模拟网页操作,处理动态网页内容。通过不断学习和实践,我们可以掌握更多的爬虫技巧,提高爬取效率和数据质量。

总结起来,利用Python爬虫可以轻松快捷地提取网页内容,满足个人、商业等各种信息需求。通过使用Python和相关库,我们可以编写强大的爬虫脚本,帮助我们从互联网中获取所需的数据。同时,要注意遵守法律和网站规定,保护个人和网络的合法权益。希望本篇文章能为读者提供基础的爬虫入门知识,并鼓励大家学习和探索更多的爬虫技术。