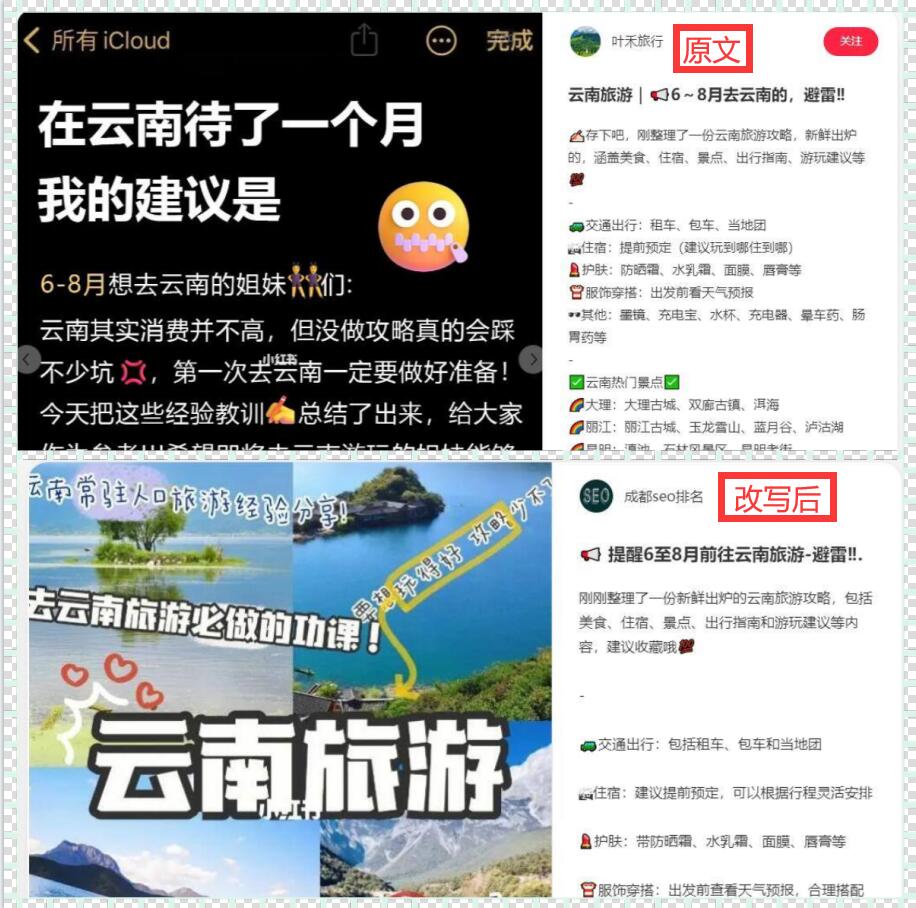
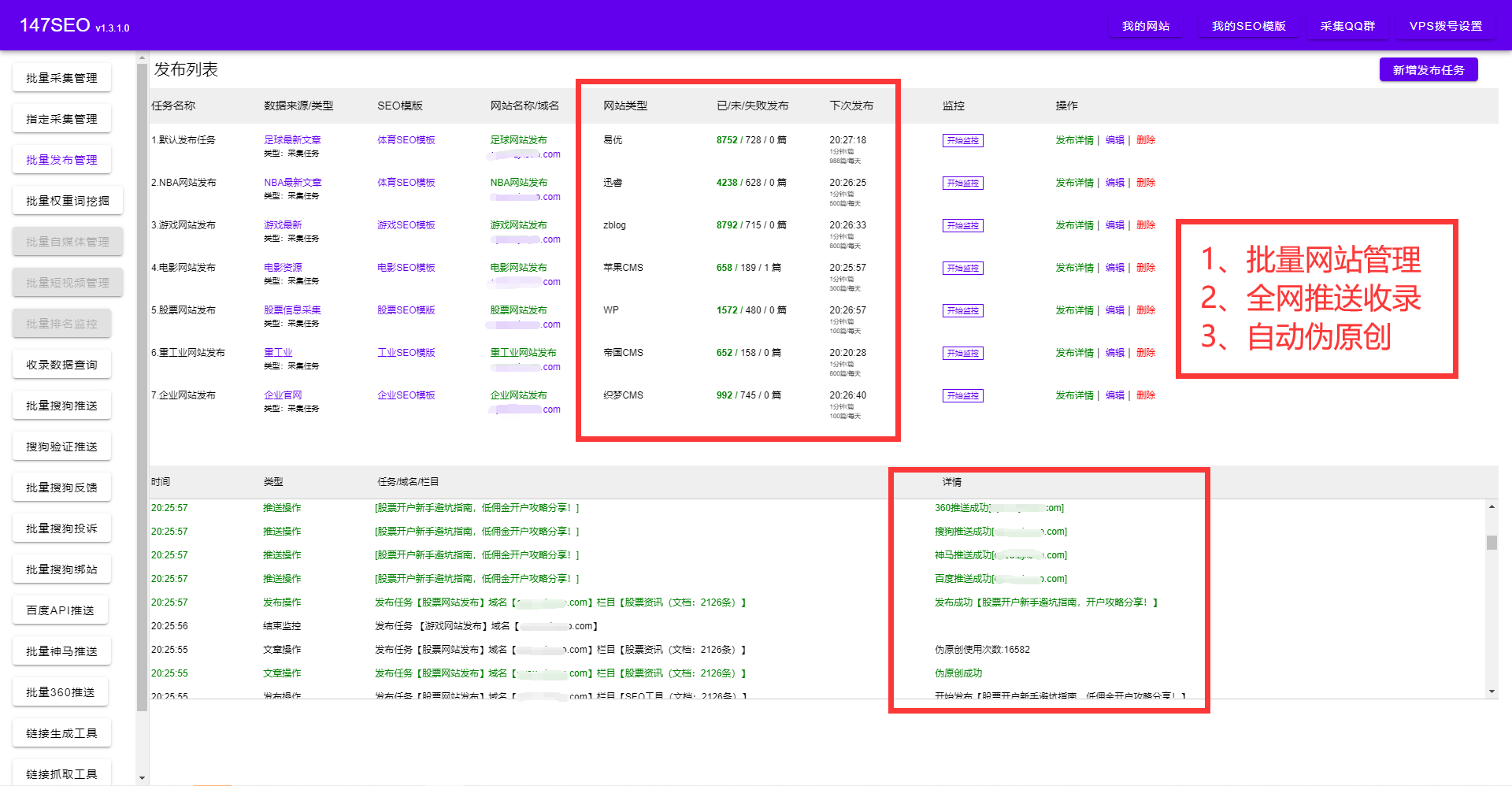
在信息爆炸的时代,数据对于我们来说变得越来越重要。许多人需要从网页上收集大量的数据,以进行进一步的分析和应用。但是,手动复制粘贴是一项耗时且乏味的工作,因此,我们需要一种自动化的方法来高效地爬取一页多条数据。

首先,我们需要利用编程语言提供的网络爬虫工具。Python是一种功能强大且易于学习的编程语言,其中包含了很多用于网络爬取的库。使用Python的requests库可以方便地发送HTTP请求,并获取所需的网页数据。
其次,我们需要了解要爬取页面的结构。现代网页通常使用HTML进行标记,通过解析HTML的标签和属性,我们可以定位到所需的数据。使用Python的BeautifulSoup库可以方便地解析HTML,并提取出需要的数据。
在编写爬虫程序时,我们需要考虑一些技巧和注意事项。首先,为了防止对网站造成过大的负担,我们应该设置适当的爬取速度和时间间隔,以避免被封IP或引起其他问题。另外,有些网站会对爬虫程序进行限制,例如通过验证码或登录验证。我们可以采取一些策略来应对这些限制,例如使用代理IP、模拟登录等。

此外,处理动态加载的数据也是一个常见的难题。现代网页通常使用JavaScript来加载数据,这就要求我们使用一些特殊的技术来处理。通过模拟浏览器行为以及使用JavaScript解释器,我们可以在爬取过程中执行JavaScript代码,获取到动态加载的数据。
最后,要保证数据爬取的效率和准确性,我们需要进行数据清洗和去重。有些网页可能会包含重复或无效的数据,我们可以使用正则表达式或其他方法对数据进行过滤和处理,以确保所得到的数据质量较高。
总结起来,数据爬取是一项高效获取信息的技术,能够帮助我们快速收集大量的数据。通过使用网络爬虫,我们可以自动化地爬取一页多条数据,并进行进一步的分析和应用。希望本文提供的技巧和建议对您有所帮助,祝您的数据爬取工作顺利!