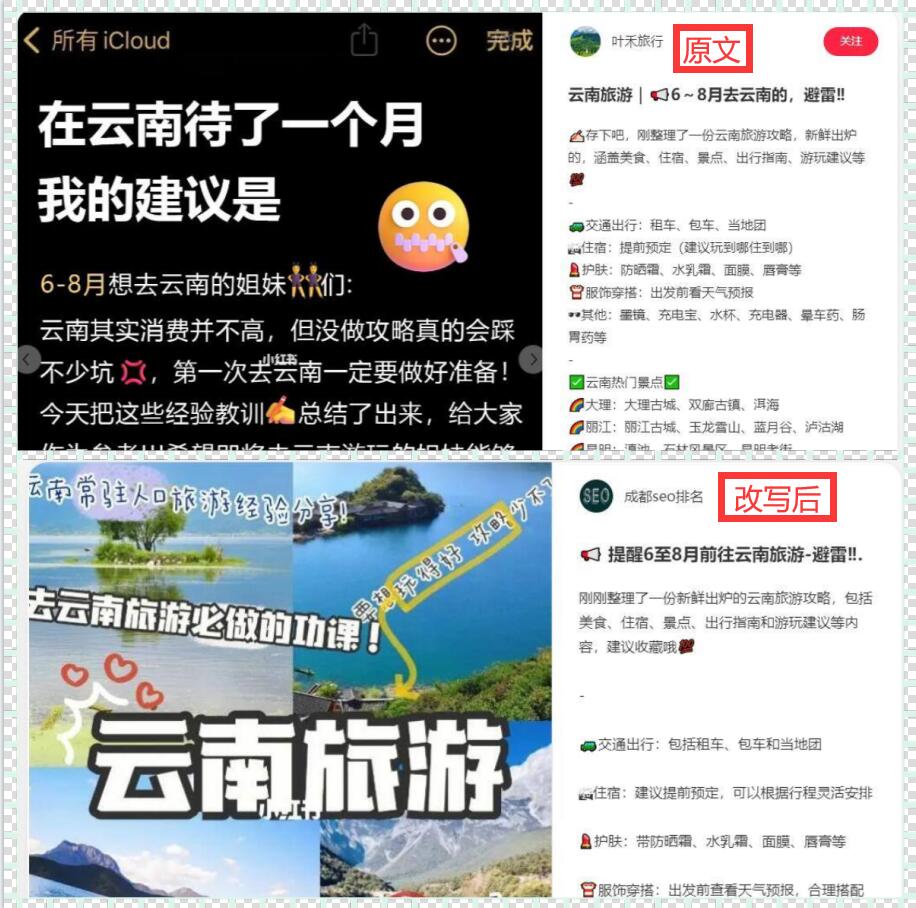
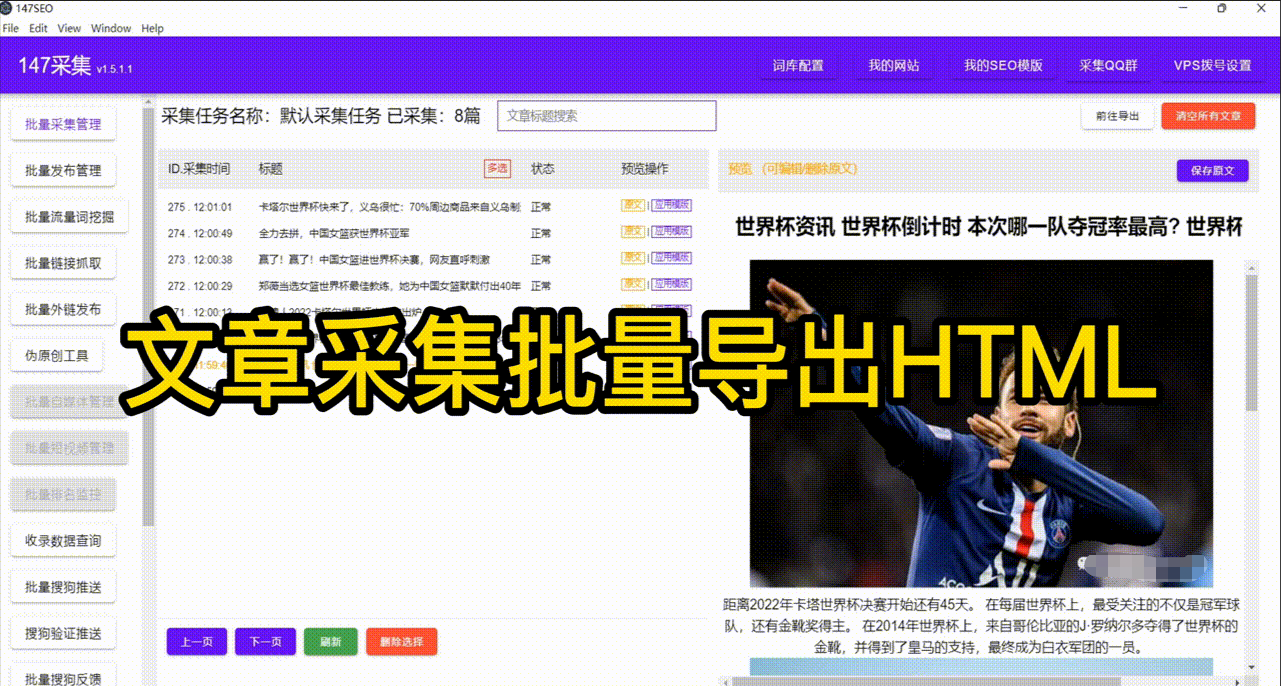
在当今信息爆炸的时代,准确、大规模地采集和分析网页数据变得至关重要。然而,手动访问和提取多个网页数据显然是一项令人畏惧的任务。好在有着强大的网络爬虫技术,我们可以自动化地完成这个过程,并快速高效地获取所需数据。

首先,为了方便地获取多个网页数据,我们需要选择合适的爬虫框架或库。目前,Python语言中最流行的爬虫框架是Scrapy,它提供了很多强大的功能和便捷的接口。通过定义好网页的URL列表和对应的数据提取规则,Scrapy可以自动化地爬取多个网页,并将提取到的数据保存到文件或数据库中。
接下来,我们需要了解如何编写爬虫脚本以及如何处理网页结构。首先,我们需要定义一个爬虫类,并在类中定义一些方法,例如start_requests()方法用于生成初始的请求对象,parse()方法用于解析网页和提取数据。使用XPath或CSS选择器等工具,我们可以方便地定位和提取所需数据。
在处理多个网页时,通常会遇到一些常见问题,例如网页的登录验证、反爬虫机制等。为了应对这些问题,我们需要学习一些高级爬虫技巧,例如使用代理IP、模拟登录、设置请求头信息等。这些技术能够帮助我们顺利地获取到需要的数据,并避免被网站的反爬虫机制SEO。

此外,为了提高爬取效率和数据质量,我们还可以使用多线程或分布式爬虫技术。多线程可以同时处理多个网页的请求和响应,从而提高爬取速度。而分布式爬虫则可以通过部署多个爬虫节点,将负载分散到不同的机器上,从而更快地完成大规模的数据采集。
最后,我们还需要注意一些道德和法律规范。在爬取多个网页数据时,我们应该尊重网站的隐私权和使用条款,并遵守相关的法律法规。同时,我们也要注意自己的爬虫行为是否给网站带来了过大的负担,以免给别人的正常访问造成影响。
总而言之,通过选择合适的爬虫框架、学习相关技术并遵守规范,我们可以高效地爬取多个网页数据,并实现大规模的数据采集。这将帮助我们更好地分析和应用数据,为各行各业的发展提供有力的支持。