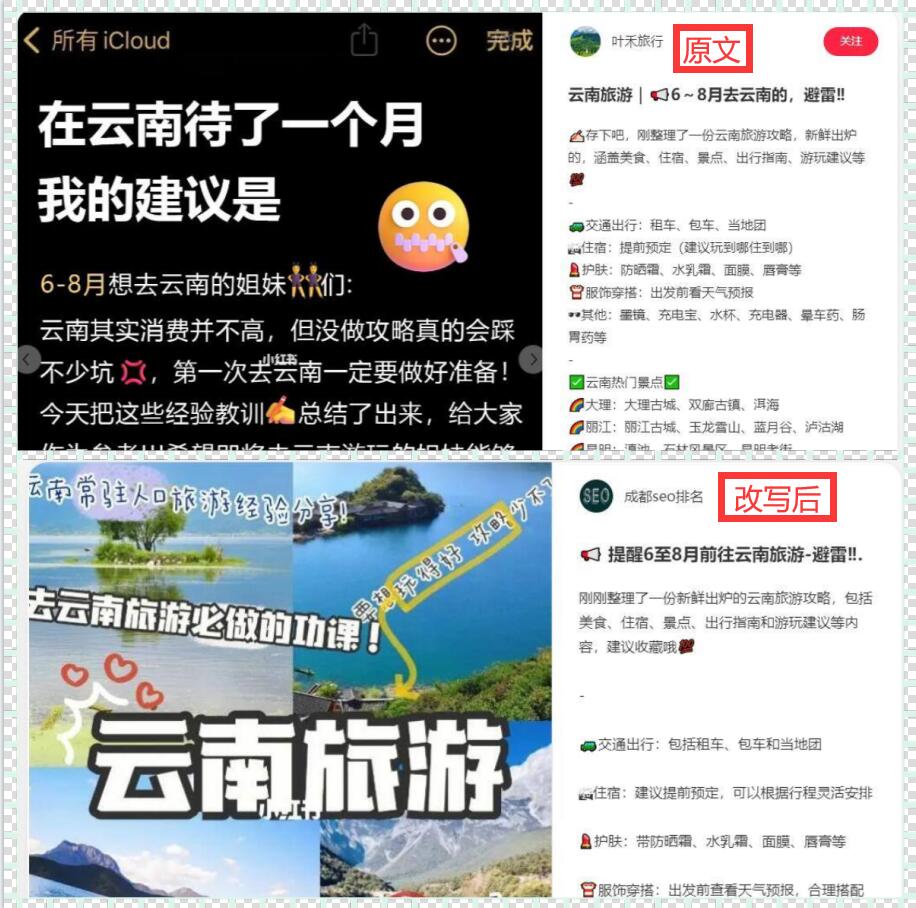
在当今信息化时代,数据变得异常重要。对于一些需要大量数据支持的项目,如市场分析、数据挖掘等,手动采集数据已经远远不够用了。而这时,网络爬虫就成为了救命稻草。本文将向您介绍如何使用爬虫技术爬取一个网站的多个页面数据,以及一些实用的操作技巧与注意事项。

首先,我们需要明确目标网站的结构和数据分布。要爬取多个页面数据,首先要了解目标网站的URL规则和页面分布。通常,网站的页面是有一定规律的,如有固定的前缀或后缀、编号等,通过分析这些规律,我们可以构造出目标页面的URL。例如,目标网站的页面URL可能是类似于http://www.example.com/page/1,http://www.example.com/page/2,...的形式,我们可以通过循环遍历的方式来爬取多个页面的数据。
其次,我们需要选择合适的爬虫工具。爬虫工具有很多种,常见的有Scrapy、BeautifulSoup、Selenium等。选择哪种工具要根据具体需求和技术水平来决定。Scrapy是一个功能强大的Python爬虫框架,适合对整个网站进行爬取;BeautifulSoup是一个解析HTML/XML文档的Python库,适合对单个页面进行解析;Selenium是一个自动化测试工具,可以模拟真实浏览器操作,适合处理一些复杂的页面。根据目标网站的特点,选择合适的爬虫工具可以提高效率和精确度。
然后,我们需要编写爬虫程序。通过调用爬虫工具提供的API,我们可以编写相应的爬虫程序来实现数据的爬取。爬虫程序的核心是发送HTTP请求,获取响应的HTML页面,并对页面进行解析提取需要的数据。通过查找目标页面的标签和属性,使用正则表达式或XPath等方式提取数据并保存到本地或数据库中。在编写程序时,要注意设置合适的请求头信息,模拟浏览器行为,防止被目标网站封禁。

此外,还有一些操作技巧和注意事项需要我们注意。首先,要合理设置爬取的时间间隔,不要给目标网站过大的负担。可以设置合适的延时时间,或者采用分布式爬取的方式。其次,要处理好目标网站的反爬措施,如设置合适的User-Agent、使用代理IP或者使用登录等方式。再次,要注意合法合规地爬取数据,遵守相关法律法规和网站的爬虫协议。最后,要注意数据的清洗和去重,确保数据的质量和准确性。
综上所述,爬取一个网站的多个页面数据需要明确目标网站的结构和数据分布,选择合适的爬虫工具,编写相应的爬虫程序,并注意一些操作技巧和注意事项。希望本文能够帮助到您,如果您对爬虫技术还有其他疑问,可以继续向我提问。