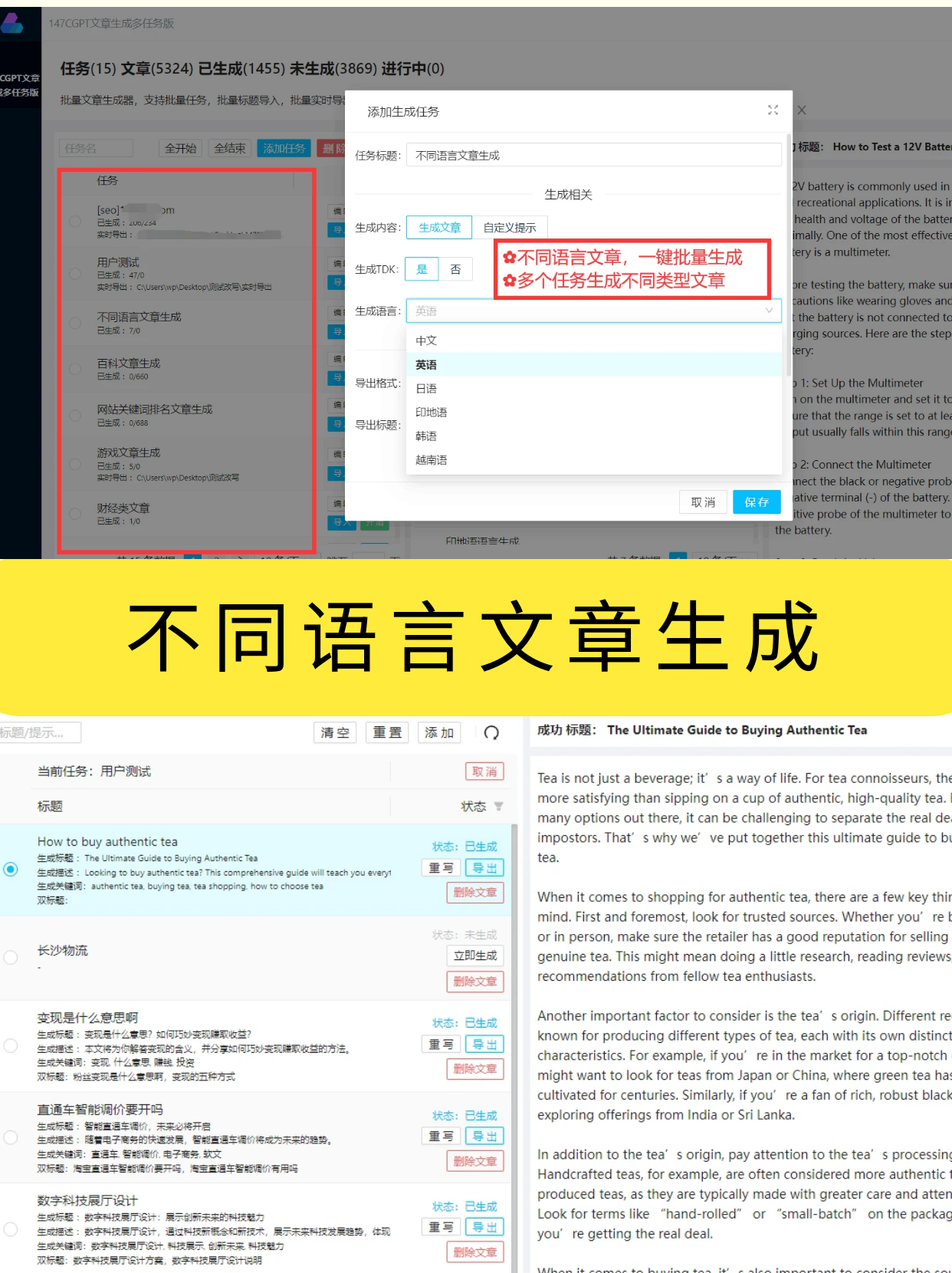
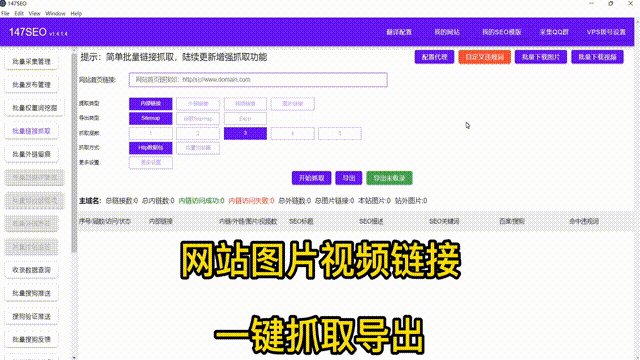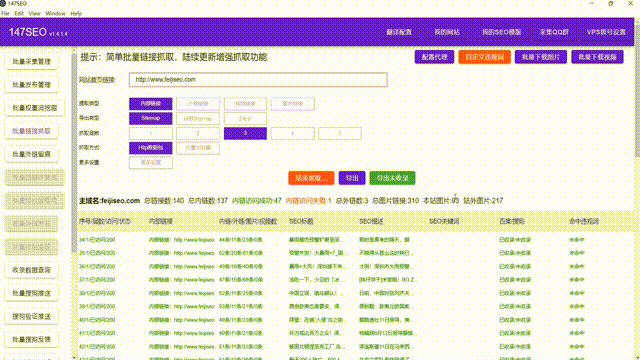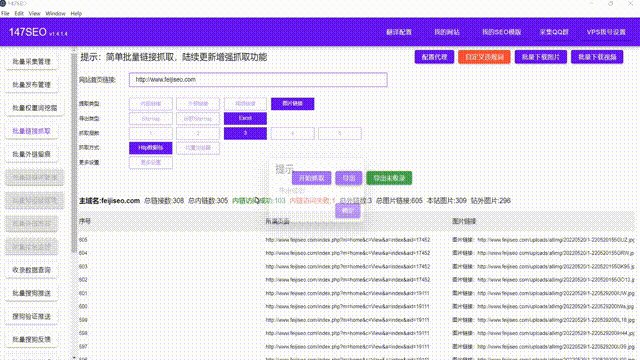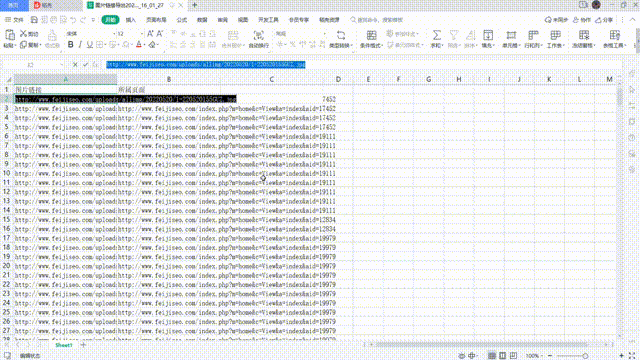
在当今信息爆炸的时代,数据成为了一种极其宝贵的ZY。大量的数据不仅可以帮助我们了解社会状况,还可以用来发现规律、预测趋势,对于企业来说更是决策的参考依据。然而,要获取大量的数据并进行分析并非易事。一种高效的方式就是通过网络爬虫从网站上爬取数据。

网络爬虫,也称为网页爬虫或网络蜘蛛,是一种自动获取网页内容的程序。通过网络爬虫,我们可以发现并解析网页上的各种信息,例如文章、图片、shiping等。使用爬虫可以大大提高数据获取效率,避免了人工复制粘贴的繁琐工作,而且还能够获取到大量无法人工获取的数据。
首先,我们需要确定要爬取的目标网站。一般来说,我们可以根据自己的需求选择合适的网站进行数据爬取。例如,如果我们想要获取某个商品的价格信息,可以选择电商网站;如果我们想要获取新闻文章的相关资讯,可以选择新闻网站。根据目标网站的不同,我们需要针对不同的网站编写相应的爬虫代码。
其次,我们需要了解目标网站的结构和数据页面的特点。每个网站的设计和结构都不尽相同,有些网站可能会对爬虫进行限制,需要我们绕过这些限制才能成功获取数据。通过查看网页源代码、分析URL参数等方式,我们可以找到目标数据所在的具体位置,并提取出所需的信息。

接下来,我们可以使用编程语言(如Python)来编写爬虫程序。通过解析HTML代码和网页上的标签和属性,我们可以抽取出所需数据,并将其保存为结构化的数据格式,如JSON。编写爬虫程序时,需要注意不要给目标网站带来巨大的负载,可以设置合理的爬取速度和爬虫的访问频率,避免对网站的正常运行造成影响。
在编写完爬虫程序后,我们可以进行数据分析。通过对爬取的数据进行清洗、整理和加工,我们可以发现数据背后的规律和趋势。数据分析可以帮助我们做出更准确的决策,提高工作效率。同时,我们还可以将数据用于机器学习和人工智能的训练,实现更加智能化的应用。
总之,通过网络爬虫从网站上爬取数据是一种高效且可行的方式。它可以帮助我们获取大量的数据,并进行数据分析,从而为我们的工作和决策提供有力支持。当然,在进行数据爬取时,我们也要遵守相应的法律和道德规范,不得获取和使用非法或违反隐私的数据。希望本文能够帮助到大家,让我们更好地利用数据来推动社会进步和个人发展。