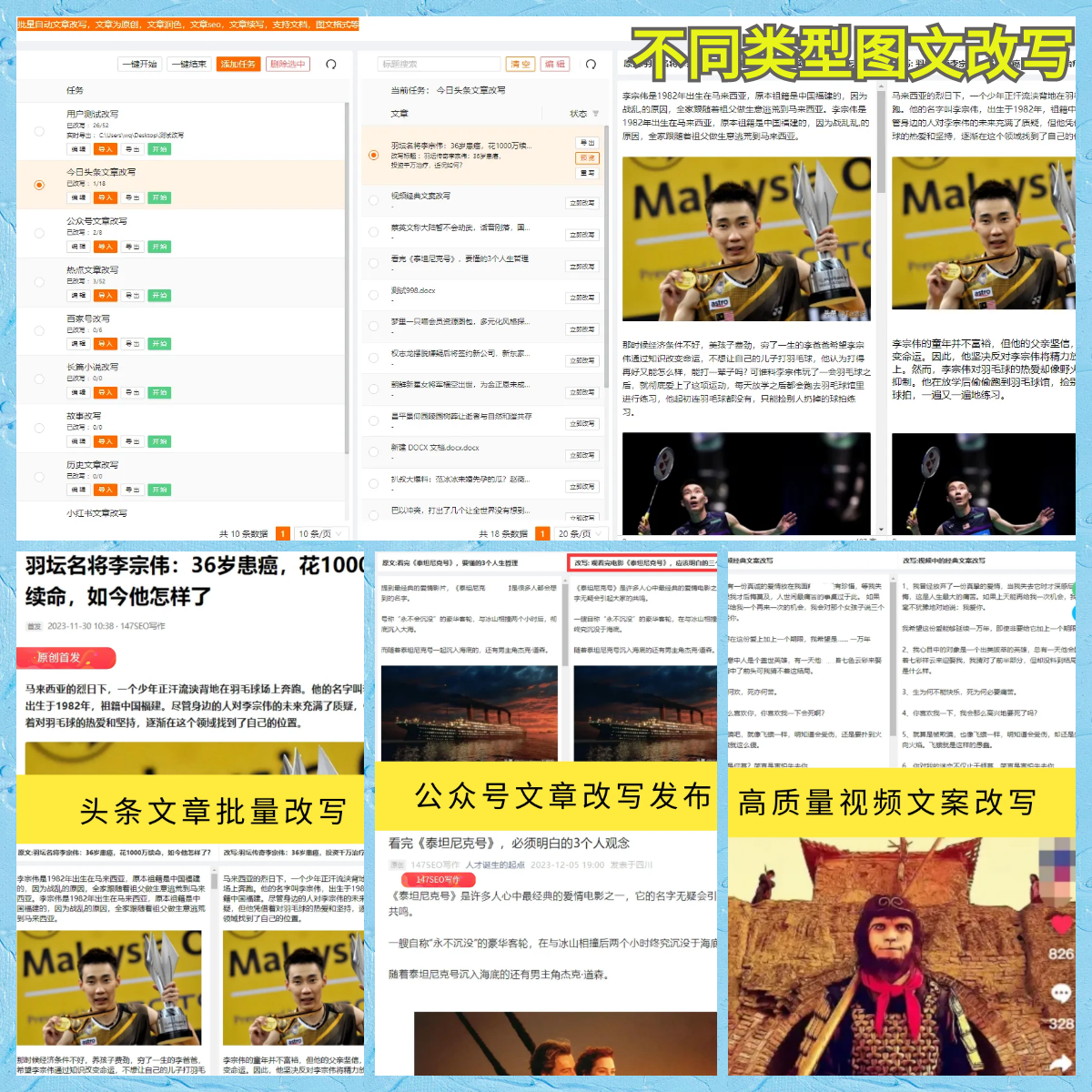
随着互联网的快速发展,人们可以轻松获取海量的数据信息。而如何从这些数据中提取出有价值的信息,成为了许多领域研究的核心问题。为了解决这一问题,网页数据爬取技术应运而生。本文将重点介绍如何通过网页数据爬取技术获取有价值的信息,并详细解释了其在不同领域的应用。
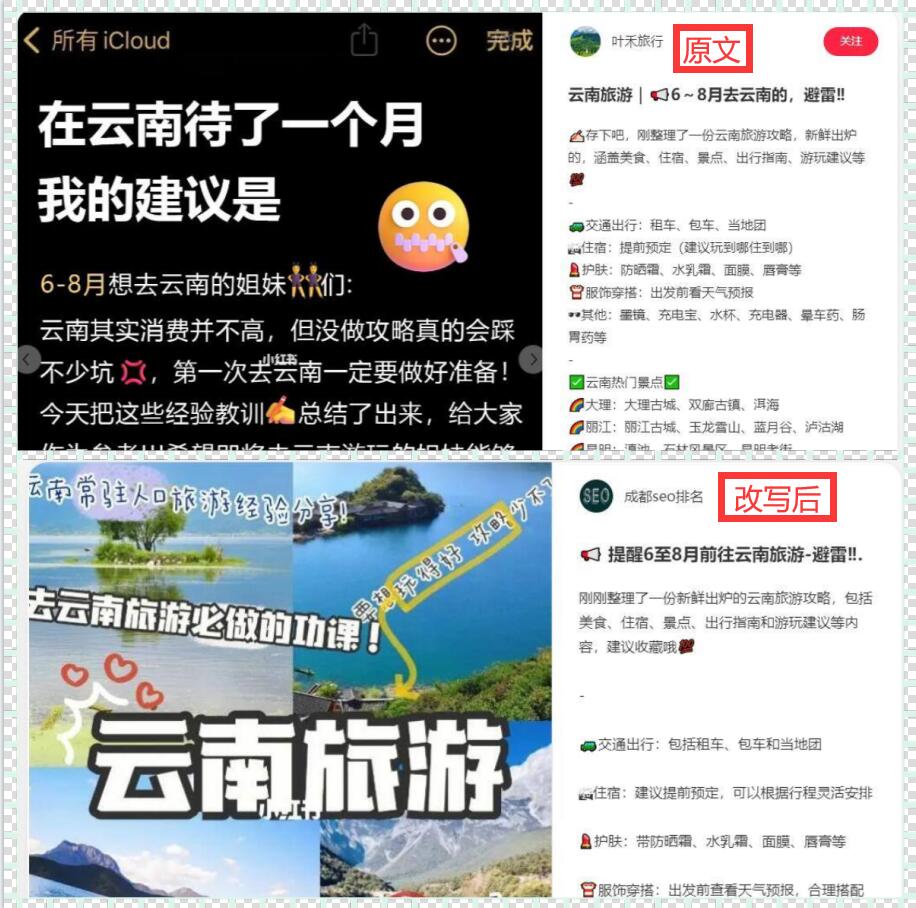
一、网页数据爬取技术的定义与原理 网页数据爬取技术,即通过程序自动访问网页并提取页面中的数据信息。它可以模拟人的浏览器行为,获取网页中的文本、图像、音频、shiping等各种类型的数据。它的原理主要包括发送HTTP请求、解析HTML代码、提取目标数据等步骤。
二、网页数据爬取技术的应用领域 1.市场研究与竞争情报 通过爬取各大电商pingtai的产品信息,可以获得市场上不同商品的销售情况、价格波动等信息,帮助企业进行市场研究和竞争情报分析。
2.舆情监测与品牌管理 通过爬取新闻媒体、luntan、微博等pingtai上的用户评论、文章等信息,可以及时了解舆论动向和用户对品牌的评价,帮助企业调整营销策略和品牌管理。
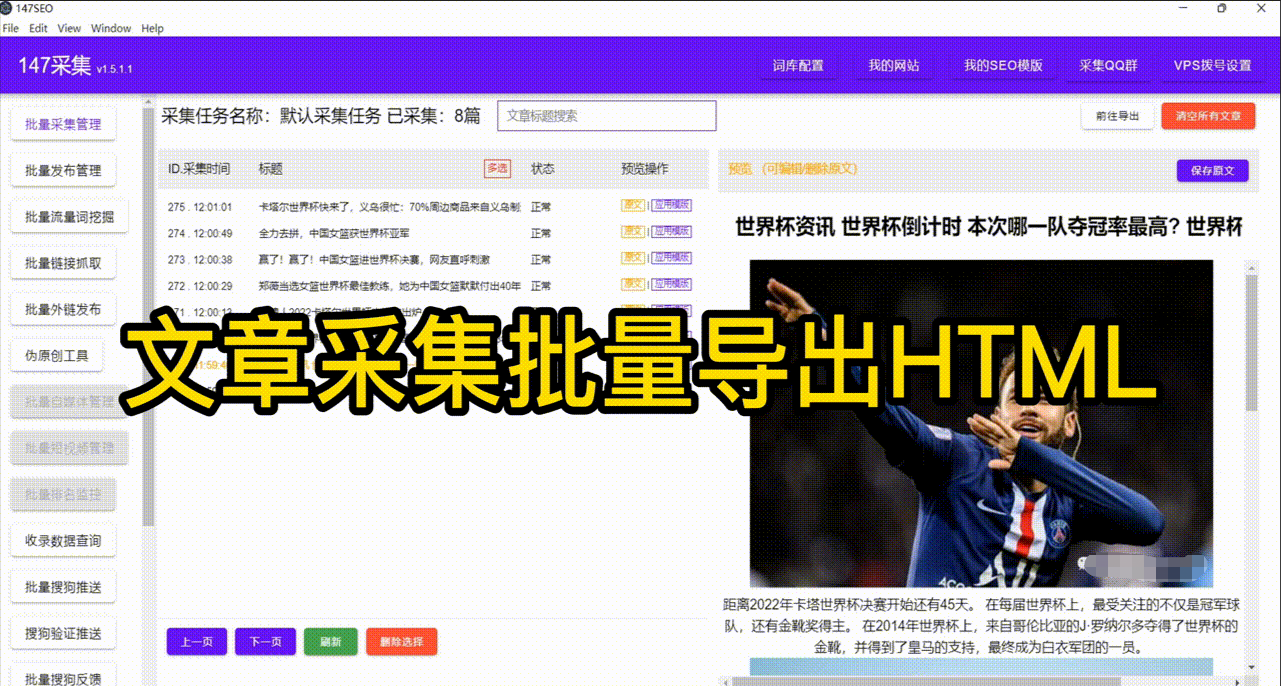
3.金融风控与投资分析 通过爬取gupiao交易所、caijing网站等平台上的gupiao行情、公司财报等信息,可以进行金融风控和投资分析,帮助投资者做出明智的投资决策。
4.yiliao健康与科研创新 通过爬取yi学数据库、科研论文等pingtai上的yiliao健康信息,可以进行疾bing预测、yi学研究等工作,为疾bing防治和科研创新提供有力支持。
三、网页数据爬取技术的优势与挑战 1.优势:网页数据爬取技术能够快速、准确地获取大量数据,避免了人工收集的复杂过程,提高了工作效率。

2.挑战:网页数据爬取技术也面临着一些挑战,如网页结构复杂、反爬机制阻碍等问题。同时,爬取过程中需要注意法律法规的合规性,避免侵犯他人的隐私和知识产权。
综上所述,网页数据爬取技术在获取有价值的信息方面发挥着重要的作用,并在市场研究、舆情监测、金融风控、yiliao健康等领域得到广泛应用。然而,我们也要认识到,网页数据爬取技术的合理使用需要遵循一定的规范和法律法规,才能更好地发挥其价值。
以上就是关于网页数据爬取的软文,希望本文对您有所帮助!